


How do we move from language models that only answer prompts to systems that can reason over million token contexts, understand real world signals, and reliably act as agents on our behalf? Google just released Gemini 3 family with Gemini 3 Pro as the centerpiece that positions as a major step toward more general AI systems. The research team describes Gemini 3 as its most intelligent model so far, with state of the art reasoning, strong multimodal understanding, and improved agentic and vibe coding capabilities. Gemini 3 Pro launches in preview and is already wired into the Gemini app, AI Mode in Search, Gemini API, Google AI Studio, Vertex AI, and the new Google Antigravity agentic development platform.
Sparse MoE transformer with 1M token context
Gemini 3 Pro is a sparse mixture of experts transformer model with native multimodal support for text, images, audio and video inputs. Sparse MoE layers route each token to a small subset of experts, so the model can scale total parameter count without paying proportional compute cost per token. Inputs can span up to 1M tokens and the model can generate up to 64k output tokens, which is significant for code bases, long documents, or multi hour transcripts. The model is trained from scratch rather than as a fine tune of Gemini 2.5.
Training data covers large scale public web text, code in many languages, images, audio and video, combined with licensed data, user interaction data, and synthetic data. Post training uses multimodal instruction tuning and reinforcement learning from human and critic feedback to improve multi step reasoning, problem solving and theorem proving behaviour. The system runs on Google Tensor Processing Units TPUs, with training implemented in JAX and ML Pathways.
Reasoning benchmarks and academic style tasks
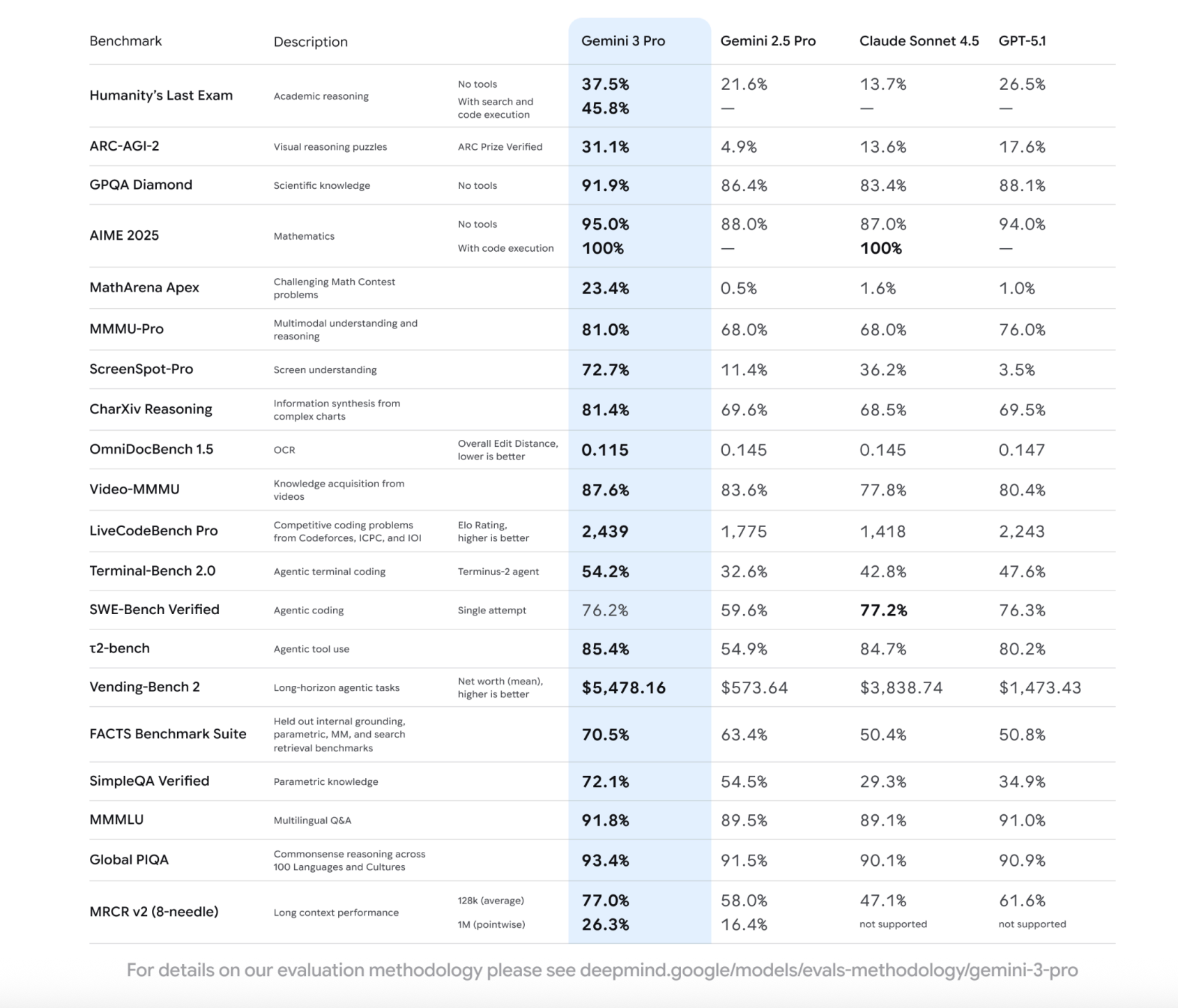
On public benchmarks, Gemini 3 Pro clearly improves over Gemini 2.5 Pro and is competitive with other frontier models such as GPT 5.1 and Claude Sonnet 4.5. On Humanity’s Last Exam, which aggregates PhD level questions across many scientific and humanities domains, Gemini 3 Pro scores 37.5 percent without tools, compared to 21.6 percent for Gemini 2.5 Pro, 26.5 percent for GPT 5.1 and 13.7 percent for Claude Sonnet 4.5. With search and code execution enabled, Gemini 3 Pro reaches 45.8 percent.

On ARC AGI 2 visual reasoning puzzles, Gemini 3 Pro scores 31.1 percent, up from 4.9 percent for Gemini 2.5 Pro, and ahead of GPT 5.1 at 17.6 percent and Claude Sonnet 4.5 at 13.6 percent. For scientific question answering on GPQA Diamond, Gemini 3 Pro reaches 91.9 percent, slightly ahead of GPT 5.1 at 88.1 percent and Claude Sonnet 4.5 at 83.4 percent. In mathematics, the model achieves 95.0 percent on AIME 2025 without tools and 100.0 percent with code execution, while also setting 23.4 percent on MathArena Apex, a challenging contest style benchmark.
Multimodal understanding and long context behaviour
Gemini 3 Pro is designed as a native multimodal model instead of a text model with add ons. On MMMU Pro, which measures multimodal reasoning across many university level subjects, it scores 81.0 percent versus 68.0 percent for Gemini 2.5 Pro and Claude Sonnet 4.5, and 76.0 percent for GPT 5.1. On Video MMMU, which evaluates knowledge acquisition from videos, Gemini 3 Pro reaches 87.6 percent, ahead of Gemini 2.5 Pro at 83.6 percent and other frontier models.
User interface and document understanding are also stronger. ScreenSpot Pro, a benchmark for locating elements on a screen, shows Gemini 3 Pro at 72.7 percent, compared to 11.4 percent for Gemini 2.5 Pro, 36.2 percent for Claude Sonnet 4.5 and 3.5 percent for GPT 5.1. On OmniDocBench 1.5, which reports overall edit distance for OCR and structured document understanding, Gemini 3 Pro achieves 0.115, lower than all baselines in the comparison table.
For long context, Gemini 3 Pro is evaluated on MRCR v2 with 8 needle retrieval. At 128k average context, it scores 77.0 percent, and at a 1M token pointwise setting it reaches 26.3 percent, ahead of Gemini 2.5 Pro at 16.4 percent, while competing models do not yet support that context length in the published comparison.
Coding, agents and Google Antigravity
For software developers, the main story is coding and agentic behaviour. Gemini 3 Pro tops the LMArena leaderboard with an Elo score of 1501 and achieves 1487 Elo in WebDev Arena, which evaluates web development tasks. On Terminal Bench 2.0, which tests the ability to operate a computer through a terminal via an agent, it reaches 54.2 percent, above GPT 5.1 at 47.6 percent, Claude Sonnet 4.5 at 42.8 percent and Gemini 2.5 Pro at 32.6 percent. On SWE Bench Verified, which measures single attempt code changes across GitHub issues, Gemini 3 Pro scores 76.2 percent compared to 59.6 percent for Gemini 2.5 Pro, 76.3 percent for GPT 5.1 and 77.2 percent for Claude Sonnet 4.5.
Gemini 3 Pro also performs well on τ2 bench for tool use, at 85.4 percent, and on Vending Bench 2, which evaluates long horizon planning for a simulated business, where it produces a mean net worth of 5478.16 dollars versus 573.64 dollars for Gemini 2.5 Pro and 1473.43 dollars for GPT 5.1.
These capabilities are exposed in Google Antigravity, an agent first development environment. Antigravity combines Gemini 3 Pro with the Gemini 2.5 Computer Use model for browser control and the Nano Banana image model, so agents can plan, write code, run it in the terminal or browser, and verify results inside a single workflow.
Key Takeaways
Gemini 3 Pro is a sparse mixture of experts transformer with native multimodal support and a 1M token context window, designed for large scale reasoning over long inputs.
The model shows large gains over Gemini 2.5 Pro on difficult reasoning benchmarks such as Humanity’s Last Exam, ARC AGI 2, GPQA Diamond and MathArena Apex, and is competitive with GPT 5.1 and Claude Sonnet 4.5.
Gemini 3 Pro delivers strong multimodal performance on benchmarks like MMMU Pro, Video MMMU, ScreenSpot Pro and OmniDocBench, which target university level questions, video understanding and complex document or UI comprehension.
Coding and agentic use cases are a primary focus, with high scores on SWE Bench Verified, WebDev Arena, Terminal Bench and tool use and planning benchmarks such as τ2 bench and Vending Bench 2.
Gemini 3 Pro is a clear escalation in Google’s strategy toward more AGI, combining sparse mixture of experts architecture, 1M token context, and strong performance on ARC AGI 2, GPQA Diamond, Humanity’s Last Exam, MathArena Apex, MMMU Pro, and WebDev Arena. The focus on tool use, terminal and browser control, and evaluation under the Frontier Safety Framework positions it as an API ready workhorse for agentic, production facing systems. Overall, Gemini 3 Pro is a benchmark driven, agent focused response to the next phase of large scale multimodal AI.
Check out the Technical details and Docs. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Max is an AI analyst at MarkTechPost, based in Silicon Valley, who actively shapes the future of technology. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI daily to translate complex tech advancements into clear, understandable insights
